Linux file systems: The challenges in recovering deleted files
These days Linux operating system is constantly growing in its popularity among a larger group of users. Its clear advantage is first of all free distribution. Moreover, this operating system offers an enormous variety of versions and their derivatives that cover diverse users' needs in devices ranging from mobile phones to supercomputers.
Linux OS uses different file systems that include Ext2, Ext3 and Ext4, XFS, ReiserFS, JFS (JFS2) etc. Linux file systems differ in functionality, each serving certain purposes. In the process of file deletion each behaves in its own way providing different recovery results and sometimes even in failed recovery.
The information given in this article helps to understand general principles of Linux OS operation and reasons for frequent failures to recover deleted files with exact sizes and names from Linux file systems. Our data recovery software allows to achieve the highest possible recovery result even in complicated cases. Please refer to software products for more information.
How data is organized?
Like most other file systems Linux file systems use block data organization. At a logical level data storages are operated in small data units – sectors – normally 512 bytes in size. You can imagine storage sectors as cells with ordinal numbers. At writing data fragments take one or more such sectors. At reading storage driver addresses this sector for the data.
To optimize disk addressing the file system combines equal sets of sectors into blocks addressable with file system driver at logical level. Minimal possible block size is one sector. Most file systems including Linux file systems use blocks as the smallest addressable disk unit. Usually, a file or its fragment smaller than one block in size takes the entire block. Some file systems like ReiserFS, however, may use remaining space inside the block to allocate small files and file fragments.
Normally, the data on a storage are organized in this way: a file is allocated into a block; if a file exceeds the block in its size the file system gives one more block to allocate the file (except for cases like with ReiserFS). Data are written into free disk blocks, not used by any files or metadata (technical information of the file system).
Free space and fragmentation
Many sequential or concurrent requests 'create file', 'append data', 'truncate data', 'delete file' make free space on the file system fragmented.
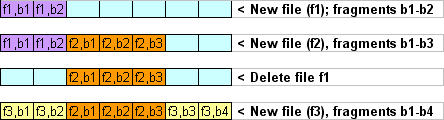
Figure 1. Fragmentation
Figure 1 shows the simplest example of fragmentation. At the time when File 3 was being written, there was no space to write file fragments sequentially, thus fragments of the same file were allocated into two not-linked free blocks. In practice, large files may consist of up to hundreds of unlinked data fragments several blocks each.
The file system doesn't wipe fragments of the file under 'delete' command immediately and rather marks the place occupied by these fragments free. This place is perceived by the new file as free to occupy. For this reason the file actually remains recoverable unless overwritten by the new one.
How fragments are linked?
The file system uses special agents describing files – information nodes (briefly – inodes) – to link information about file fragments. This information includes description of object type, size, allocation table/list/tree.
Reading an inode the file system can determine the type of the object and decide on further operations – read/write/handle. Object size tells about the number of the blocks occupied by the object. And finally object allocation gives information about actual locations of data blocks.
The object allocation data are organized in the following way: The key part of these data is an array, a list or a B-tree of pointers to data blocks or to continuous fragments of blocks. The first part or root of this information is stored as part of inode.
Problem of restoring
Commonly, Linux file systems clean a part of inode information after file deletion. They fill information about object size, object type/mode and allocation with zeros resulting in loss of all information about the file. Let's assume, that files 2 and 3 in Figure 1 are RAW encrypted files without headers, and that both took full blocks, and both were deleted. As a result no information about file allocation remained making impossible for data recovery software to detect the boundaries of file 2 and file 3. In practice situations that aggravate recovery are, unfortunately, too common for Linux file systems. This is usually influenced by such factors as heavy files fragmentation.
The solution
Luckily, data recovery software offer a set of recovery methods, but with no guarantees of 100% result. They include:
-
Analysis of a file system journal. Previous versions of file descriptors may still remain in the journal.
-
Analysis of incomplete structures. The software can predict file system files by non-wiped fragments of file metadata which may still be on the disk.
-
Signature-based search: The software searches known file fragments and makes assumption as to contents of the following fragments. But often recovery results don't give exact file sizes, except for cases when a file header which contains file size in itself is found. This method is helpless for cases of heavy fragmentation.
-
Statistical fragments analysis: The software makes assumption of fragment links basing on statistical methods of data analysis. This method can be helpful for homogenic files (most bmp pictures, some archives etc.), but is helpless for heterogenic contents (like CD/DVD images etc).
-
Search for lost file system structures: The software finds lost structures of the file system helping to determine the layout of lost fragments.
If you plan to conduct data recovery by yourself, be ready to do a lot of manual work with analysis of unnamed files or file fragments, as most data recovery software often yield incomplete recovery after restoring from Linux file systems.
UFS Explorer data recovery products are developed with powerful mechanisms including IntelliRAW™ search by signatures allowing users to recognize file types and analysis of file system structures. Efficient software techniques give an opportunity to achieve the highest recovery result with minimum effort.
Last update: August 5, 2022