Визначення порядку дисків сховища NAS на базі XFS
Зазвичай пристрої NAS, такі як Buffalo LinkStation і TeraStation, Iomega StorCenter і Synology, використовують програмний RAID, який складається із розділів з даними – (найбільших розділів) кожного з дисків, що становлять сховище. Тоді файлова система XFS розподіляється по цих розділах з даними. Таким чином, щоб правильно зібрати конфігурацію RAID для подальшого відновлення даних, користувачі повинні знати правильний порядок дисків-складників RAID-системи, на основі якої працює NAS.
Ця стаття покликана пояснити, як можна визначити порядок дисків у чотридисковому NAS із на основі XFS від Buffalo TeraStation, Iomega StorCenter, Synology і аналогічних моделях NAS.
Шляхи і засоби
Перш ніж приступити до відновлення даних із NAS на основі XFS, слід з'ясувати порядок дисків RAID і параметри масиву.
Одним із можливих методів є визначення порядку накопичувачів є аналіз їх шістнадцяткового вмісту відповідно до відомих фрагментів даних на початку розділів із даними. Ефективні засоби для такого аналізу надає CI Hex Viewer. Водночас, деякі просунуті додатки для відновлення даних пропонують набагато простіший спосіб визначення параметрів RAID – автоматичне зібрання сховища.
Як правило, пристрої NAS не допускають прямого низькорівневого доступу до своїх файлових систем, і рішення на основі XFS не є винятком. З огляду на це, необхідно розібрати сховище і підключити його диски до ПК. Докладні інструкції ви можете знайти у статті Як визначити тип інтерфейсу жорсткого диска та приєднати його до ПК для відновлення даних. Крім того, можна керуватися запропонованими відеоуроками, щоб підключити накопичувачі до материнської плати комп’ютера або приєднати їх за допомогою адаптера USB до SATA/IDE.
Автоматичне визначення параметрів RAID
Мережеві сховища на основі XFS зазвичай застосовують програмні конфігурації MD-RAID (Multiple Devices). Такі конфігурації RAID створюються за допомогою відомої утиліти mdadm і включають в себе лінійні (JBOD), дзеркальні (RAID 1), конфігурації на основі чергування (RAID 0), RAID 5 та RAID 6. Ця програма створює псевдорозділи з метаданими, яких цілком достатньо для автоматичної побудови RAID.
SysDev Laboratories пропонує UFS Explorer як ефективне програмне забезпечення, яке підтримує автоматичне розпізнавання, відтворення і відновлення даних із програмних RAID. UFS Explorer RAID Recovery було розроблено спеціально для роботи зі складними RAID-системами, в той час як UFS Explorer Professional Recovery забезпечує професійний підхід до відновлення даних з різноманітних пристроїв, включаючи RAID-масиви різної складності. Більш детальну інформацію про продукти можна отримати звернувшись до у технічних характеристик відповідної програми.
Для автоматичної побудови RAID за допомогою UFS Explorer RAID Recovery необхідно виконати наступні кроки:
- Завантажте, встановіть та запустіть програмне забезпечення;
- Підключіть диски NAS до хост-комп'ютера або відкрийте файли образів дисків в інтерфейсі програми;
- Програмне забезпечення автоматично збере RAID і додасть сховище до списку пристроїв для подальших операцій.
Якщо автоматичне виявлення RAID відключене в налаштуваннях програми, слід виконати наступне:
- Відкрийте RAID Builder, виберіть будь-який розділ з даними програмного RAID і додайте його в якості компонента віртуального RAID;
- Після додавання розділу і виявлення метаданих MD програма запитає, чи потрібно зібрати RAID автоматично;
- Натисніть "Так" і програма завантажить розділи диска в правильному порядку та з коректними параметрами RAID;
- Натисніть кнопку "Побудувати RAID-масив", щоб змонтувати цей RAID в UFS Explorer для подальших операцій.
Зверніть увагу: Якщо RAID-параметри NAS були змінені на інший рівень RAID, порядок дисків або розмір страйпу, попередню конфігурацію RAID доведеться задати вручну. Натисніть "Ні" в діалоговому вікні програмного забезпечення, відмовтеся від автоматичного зібрання RAID і використовуйте ручний режим визначення параметрів RAID.
Аналіз вмісту дисків
Ще одним способом визначити параметри RAID і з'ясувати точний порядок розташування дисків в RAID є проведення поглибленого аналізу вмісту дисків. CI Hex Viewer надає ефективні засоби для якісного низькорівневого аналізу даних.
Для підготовки до процедури необхідно виконати наступні дії:
Користувачі Linux: не можна монтувати файлові системи накопичувачів NAS!
Користувачі Mac: уникайте будь-якої діагностики, виправлення помилок і подібних операцій на дисках за допомогою дискової утиліти!
- Завантажте ПК, встановіть та запустіть CI Hex Viewer
Windows XP і старіші версії: запустіть програму від імені адміністратора;
Windows Vista/7/8/10 з UAC: запустіть програму від імені адміністратора за допомогою контекстного меню;
macOS: увійдіть як системний адміністратор під час запуску програми;
Linux: з командного рядка запустіть 'sudo cihexview' або 'su root-c cihexview'.
- Натисніть кнопку "Відкрити", оберіть опцію "Фізичний диск"; відкрийте розділ з даними кожного з дисків NAS.
Кожен диск NAS має однакову структуру розділів: 1-3 невеликих "системних " розділи (із загальним розміром близько декількох гігабайт) та великий розділ з даними (зазвичай більше 95% від загальної ємності накопичувача). Для отримання додаткової інформації щодо розташування розділів, будь ласка, відвідайте цю сторінку.
Конфігурація RAID і просунутий спосіб визначення порядку дисків
Щоб розпочати аналіз вмісту дисків, відкрийте шістнадцяткове представлення кожного розділу з даними всіх дисків NAS в CI Hex Viewer.
Ви можете побачити приклад аналізу вмісту для стандартної конфігурації RAID 5 із розміром страйпу 64 КБ і файловою системою XFS.
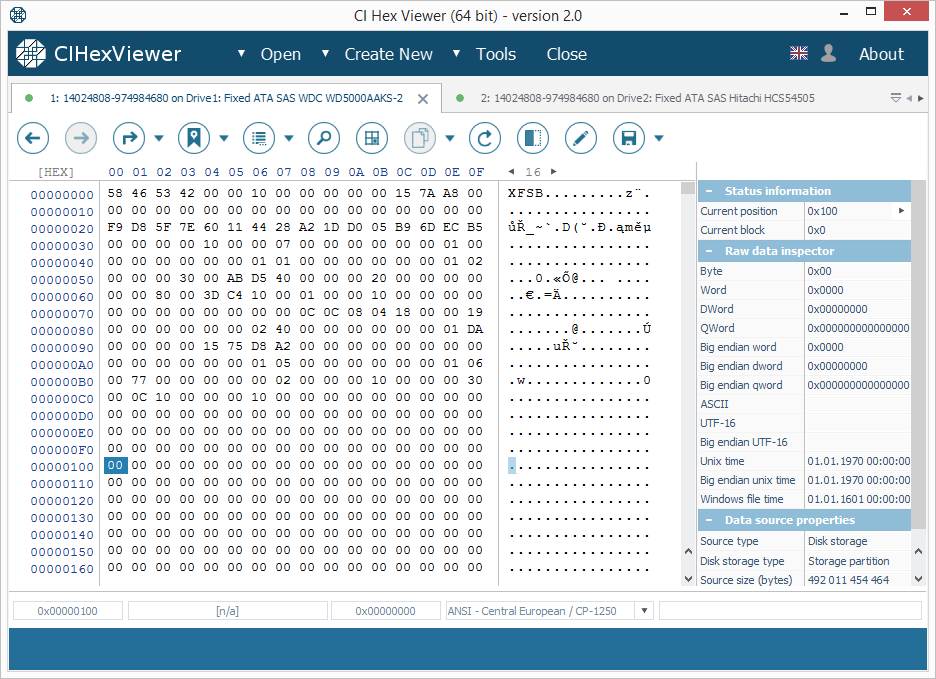
Стартовий блок (або суперблок) файлової системи XFS містить рядок "XFSB" на початку, значення параметрів файлової системи і безліч нулів. Допустимий суперблок ніколи не містить ненульові дані в діапазоні від 0x100..0x200 байт. Ця властивість дозволяє легко визначити валідність суперблоку.
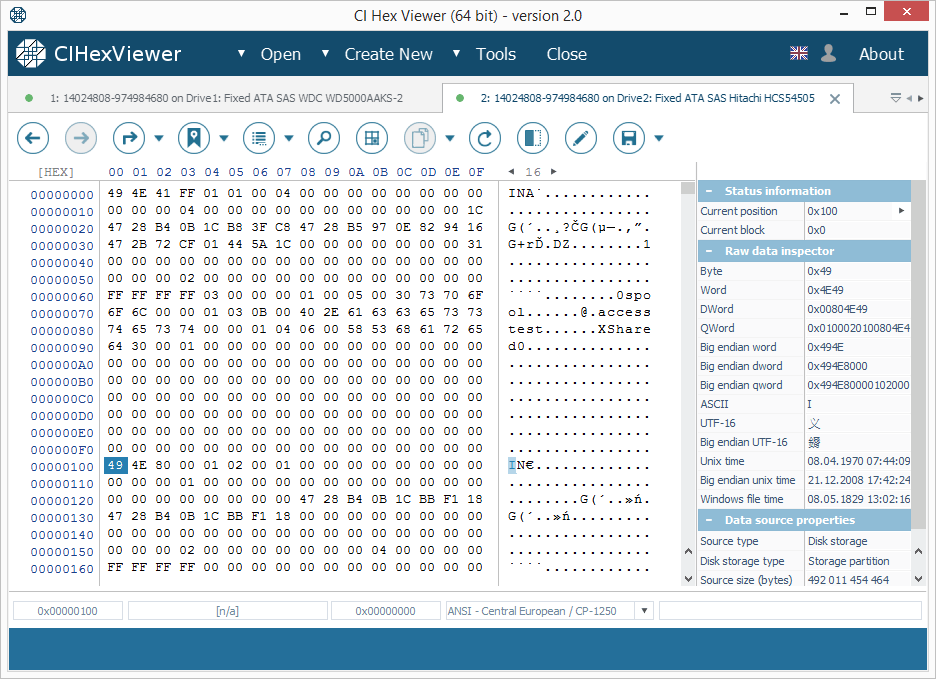
У цій файловій системі XFS блок індексних дескрипторів знаходиться за зміщенням 64 КБ. В конфігураціях RAID 0 та RAID 5 зі стандартним розміром страйпу 64K блок індексних дескрипторів розташований за нульовим зміщенням розділу даних Drive2.
Індексні дескриптори можна визначити за рядком "IN" (послідовність байтів "49 4E") на початку кожного 256 (0x100) байтових блоків. Кожен індексний дескриптор описує об'єкт файлової системи.
Верхня цифра третього байта визначає тип об'єкта. 4X байт позначає директорію, а 8X – файл.
На Рис. 2 перший індексний дескриптор позначає директорію, а другий – файл.
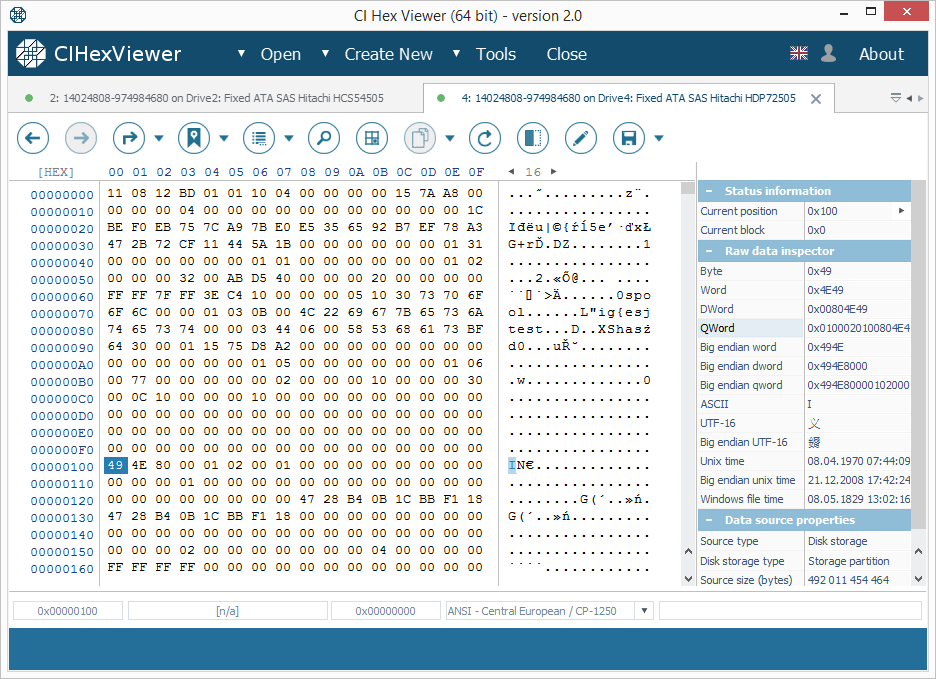
Блок парності містить суміш даних з блоків даних інших дисків. Це може виглядати як "сміття" з видимими фрагментами даних з блоків даних.
Навіть якщо блок парності містить допустимий рядок "XFSB", на відміну від суперблоку, він містить ненульові дані в діапазоні 0x100... 0x200 байт; це відрізняє його від суперблоку. Зверніть також увагу, що блок парності зазвичай містить набагато більше ненульових байтів.
Відтак, використовуючи цей відомий вміст і припускаючи, що початковий блок є першим блоком розділу даних даного диска, можна визначити конфігурацію RAID:
RAID 5:
- Тільки один перший блок буде містити суперблок (Рис.1);
- Якщо розмір страйпу становить 64 КБ (стандартний для Terastation), один з перших блоків буде містити індексні дескриптори; перший індексний дескриптор вказує на директорію (кореневу папку). Якщо коренева папка містить кілька файлів, їх імена задаються в тілі індексного дескриптора (як на Рис. 2);
- Стартовий блок третього диска буде містити дані або таблицю індексних дескрипторів;
- Стартовий блок четвертого диска буде містити парність (рис. 3);
- Застосування операції XOR до байтів із початкових блоків кожного диска в одній і тій же позиції байта дає нульовий результат.
Можна визначити конфігурацію RAID 5 як RAID із єдиним суперблоком у стартовому блоці і парністю. Операція XOR над байтами кожного стартового блоку в одній і тій же позиції байта дає нульовий результат.
Порядок розташування накопичувачів наступний: накопичувач із суперблоком – перший; накопичувач із кореневим каталогом – другий; накопичувач із парністю – четвертий; накопичувач, що залишився – третій. Процедура перевірки парності включає в себе наступні кроки:
- Виберіть зміщення розділу з ненульовими даними;
- Запустіть калькулятор (наприклад, стандартний калькулятор Windows);
- Виберіть "Вид" як "Інженерний" або "Програміст", та перейдіть з режиму "Dec" в режим "Hex";
- Введіть шістнадцяткову цифру з першого диска і натисніть кнопку "Xor";
- Введіть шістнадцяткову цифру з наступного диска з точно таким же зміщенням і знову натисніть "Xor";
- Повторіть процедуру до останнього диска. Перш ніж ввести цифру з останнього диска, калькулятор повинен показати число, що збігається із зазначеним у відповідній позиції останнього диска. Операція "Xor" дасть нуль.
Ненульове значення для будь-якого зі зміщень вказує або на помилку в обчисленні, або на відсутність парності.
RAID 0:
- Тільки один перший блок містить суперблок (Рис.1);
- Якщо розмір страйпу становить 64 КБ (стандартний для Terastation), один з перших блоків буде містити індексні дескриптори; перший індексний дескриптор повинен вказувати на каталог (кореневу папку). Якщо кореневий каталог містить файли, то їх імена задаються в індексного дескриптора (як на Рис. 2);
- Інші блоки не містять інших суперблоків або парності;
- Інші диски можуть містити більше індексних дескрипторів у першому блоці.
Конфігурацію RAID 0 можна визначити як RAID з одним суперблоком в стартовому блоці і без парності.
Порядок розташування дисків наступний: диск із суперблоком – перший; диск із кореневим каталогом – другий. 3-й і 4-й диски не можуть бути ідентифіковані відразу, але Ви можете спробувати обидва і з'ясувати, який з них є правильним.
RAID 10/0+1:
- Перші блоки двох накопичувачів містять допустимий суперблок (Рис. 1);
- Інші два диски містять дані в стартовому блоці і в разі розміру страйпу 64 КБ – індексні дескриптори.
Конфігурацію RAID 10/0+1 можна визначити як RAID із двома суперблоками в стартових блоках.
Порядок розташування накопичувачів наступний: накопичувач із суперблоком – перший, накопичувач без суперблоку (дані або індексні дескриптори) – другий. Ця конфігурація має дві такі пари, і обидві вони можуть бути використані для відновлення даних.
RAID 1 і багатоскладові сховища:
- Перші блоки кожного накопичувача містять допустимий суперблок (Рис.1).
Можна визначити RAID 1 і багатоскладове сховище як RAID із суперблоками у всіх стартових блоках.
Порядок накопичувачів наступний: Будь-який диск з RAID 1 дає всі дані. У разі багатоскладового сховища кожен диск має окрему валідну файлову систему.
Якщо процедура аналізу дає суперечливий результат, і Ви все ще не впевнені щодо порядку дисків, спробуйте всі комбінації та оберіть відповідний.
Зверніть увагу: Програмне забезпечення UFS Explorer не вносить змін до даних сховища. Ви можете спробувати різні комбінації RAID, поки не отримаєте необхідний результат.
Заключні зауваження
Правильно визначивши конфігурацію RAID, застосовану до накопичувачів NAS, можна переходити до власне процедури відновлення даних. Весь процес пояснюється поетапно в інструкції щодо відновлення даних із NAS та продемонстрований у відеокерівництві по відновленню із NAS.
Однак у разі фізичного пошкодження накопичувачів для уникнення втрати даних настійно рекомендується відправити NAS до спеціалізованої лабораторії для відновлення даних.
Якщо Ви не впевнені, що зможете самостійно виконати процедуру відновлення даних або маєте сумнів щодо конфігурації RAID Вашого NAS, зверніться за професійними послугами SysDev Laboratories.
Останнє оновлення: 19 серпня 2022