Identifizierung der Laufwerksreihenfolge in einem XFS-basierten NAS
Im Großen und Ganzen verwenden NAS-Geräte, wie Buffalo LinkStation und TeraStation, Iomega StorCenter und Synology, Software-RAID, das aus Datenpartitionen (den größten Partitionen) aller Festplatten, die den Speicher ausmachen, aufgebaut ist. Dann wird das XFS-Dateisystem über diese Datenpartitionen verteilt. Damit man die RAID-Konfiguration für die weitere Datenrettung ordnungsgemäß zusammenstellen kann, muss man die richtige Reihenfolge der Festplatten, die das RAID-System bilden, auf das sich die NAS-Box stützt, kennen.
In dem folgenden Artikel wird erläutert, wie die Reihenfolge der Laufwerke in einem XFS-basierten NAS mit vier Festplatten von Buffalo TeraStation, Iomega StorCenter, Synology und ähnlichen NAS-Modellen ermittelt werden kann.
Wege und Mittel
Bevor Sie mit der Datenwiederherstellung auf einem XFS-basierten NAS beginnen, sollten Sie die Reihenfolge der RAID-Laufwerke und RAID-Parameter bestimmen.
Eine mögliche Methode zur Identifizierung der Reihenfolge der Festplatten besteht darin, ihren hexadezimalen Inhalt in Übereinstimmung mit bekannten Datenfragmenten an den Anfängen der Datenpartitionen zu analysieren. Wirksame Mittel für solche Analyse werden von CI Hex Viewer bereitgestellt. Gleichzeitig bieten einige fortschrittliche Datenwiederherstellungsanwendungen eine wesentlich einfachere Möglichkeit, RAID-Parameter zu identifizieren – die automatische RAID-Erkennung.
In der Regel ermöglichen NAS-Geräte keinen direkten Low-Level-Zugriff auf ihre Dateisysteme, und XFS-basierte NAS-Lösungen bilden keine Ausnahme. Daher sollten Sie den Speicher zerlegen und die Laufwerke an einen PC anschließen. Lesen Sie bitte Wie man den Schnittstellentyp einer Festplatte identifiziert und diese zur Datenwiederherstellung mit einem PC verbindet für detaillierte Anweisungen. Sie können sich auch auf die bereitgestellten Video-Tutorials verlassen, um die Laufwerke an das Motherboard des Computers anzuschließen oder sie extern über einen USB-zu-SATA/IDE-Adapter zu verbinden.
Automatische Erkennung von RAID-Parametern
XFS-basierte Netz-gebundene Speicher anwenden normalerweise MD-Software-RAID-Konfigurationen (Multiple Devices). Solche RAID-Konfigurationen werden mithilfe des bekannten mdadm-Programms erstellt und umfassen lineare Konfigurationen (JBOD), Stripe-Konfigurationen (RAID 0), Mirror-Konfigurationen (RAID 1), RAID 5- und RAID 6-Konfigurationen. Dieses Programm erstellt Pseudopartitionen mit Metadaten, die ausreichen, um RAID automatisch zu erstellen.
SysDev Laboratories bietet UFS Explorer als leistungsstarke Software an, die die automatische Erkennung, Rekonstruktion und Datenrettung von Software-RAID unterstützt. UFS Explorer RAID Recovery wurde speziell für die Arbeit mit komplexen RAID-Systemen entwickelt. UFS Explorer Professional Recovery bietet einen professionellen Ansatz für die Datenwiederherstellung auf verschiedenen Geräten, einschließlich RAID-Sets unterschiedlicher Komplexität. Weitere Informationen finden Sie in den technischen Daten des entsprechenden Produkts.
Um RAID automatisch mithilfe von UFS Explorer RAID Recovery aufzubauen, sollte man folgendermaßen vorgehen:
- Laden Sie die Software herunter, installieren Sie sie und führen Sie sie aus.
- Verbinden Sie die NAS-Laufwerke mit dem Host-Computer oder öffnen Sie die Disk-Image-Dateien in der Programmoberfläche.
- Die Software stellt RAID automatisch zusammen und fügt den Speicher zur Liste der Geräte für weitere Vorgänge hinzu.
Wenn die automatische RAID-Erkennung in den Programmeinstellungen deaktiviert ist, gehen Sie wie folgt:
- Öffnen Sie RAID Builder, wählen Sie eine beliebige Datenpartition des Software-RAIDs aus und fügen Sie sie als Komponente eines virtuellen RAIDs hinzu.
- Sobald die Partition hinzugefügt und MD-Metadaten erkannt wurden, fragt die Software, ob das RAID automatisch zusammengestellt werden soll.
- Drücken Sie "Ja" und das Programm lädt die Festplattenpartitionen in der richtigen Reihenfolge und mit den richtigen RAID-Parametern.
- Klicken Sie auf "RAID bilden", um dieses RAID in UFS Explorer für weitere Vorgänge bereitzustellen.
Beachten Sie: Wenn die RAID-Parameter von NAS auf einen anderen RAID-Level, eine andere Laufwerksreihenfolge oder eine andere Stripe-Größe zurückgesetzt wurden, muss die vorherige RAID-Konfiguration manuell festgestellt werden. Klicken Sie im Softwaredialog auf "Nein", lehnen Sie die automatische RAID-Zusammenstellung ab und verwenden Sie manuelles Definieren der RAID-Parameter.
Analyse des Inhalts der Festplatten
Eine andere Möglichkeit, RAID-Parameter zu ermitteln und die Reihenfolge der Laufwerke in RAID genau zu bestimmen, besteht in einer eingehenden Analyse des Inhalts der Festplatten. CI Hex Viewer bietet effektive Mittel für die qualitative Analyse von Daten auf niedriger Ebene.
Zur Vorbereitung auf das Verfahren sollten folgende Aktionen durchgeführt werden:
Linux-Benutzer: Mounten Sie Dateisysteme von NAS-Festplatten nicht!
Mac-Benutzer: Vermeiden Sie Diagnose-, Reparatur- und ähnliche Vorgänge auf Festplatten mithilfe von Disk Utility!
- Starten Sie den PC, installieren Sie CI Hex Viewer und führen Sie die Anwendung aus.
Windows XP und früher: Führen Sie die Software als Administrator aus.
Windows Vista/7/8/10 mit UAC: Führen Sie die Software als Administrator über das Kontextmenü aus.
macOS: Melden Sie sich beim Programmstart als Systemadministrator an.
Linux: Führen Sie in der Befehlszeile 'sudo cihexview' oder 'su root -c cihexview' aus.
- Klicken Sie auf "Öffnen" und dann "Physische Festplatte" (Strg + Umschalt + "O"). Öffnen Sie die Datenpartition jedes NAS-Laufwerks.
Jedes NAS-Laufwerk hat dieselbe Partitionsstruktur: 1-3 kleine "System"-Partitionen (mit einer Gesamtgröße von mehreren Gigabyte) und eine große Datenpartition (normalerweise über 95% der Gesamtkapazität des Laufwerks). Für weitere Informationen über das Layout der Partitionen, lesen Sie bitte den angegebenen Artikel.
RAID-Konfiguration und erweiterte Erkennung der Reihenfolge von Festplatten
Öffnen Sie zum Analysieren des Festplatteninhalts die hexadezimale Ansicht jeder Datenpartition aller NAS-Laufwerke in CI Hex Viewer.
Sie sehen ein Beispiel für eine Inhaltsanalyse für eine RAID 5-Standardkonfiguration mit einer Stripe-Größe von 64 KB und dem XFS-Dateisystem.
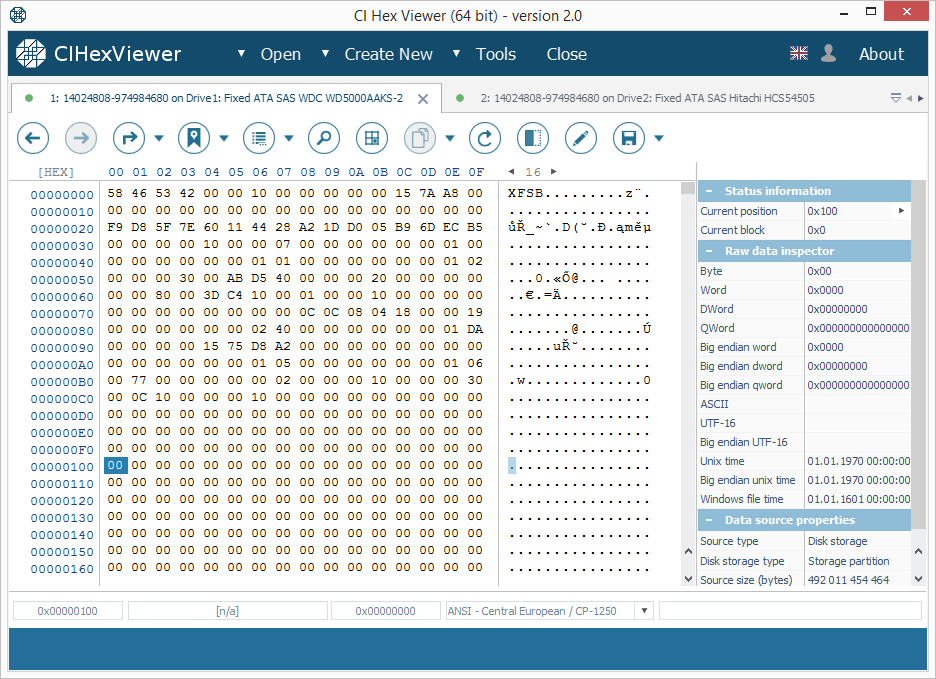
Der Startblock (oder der Superblock) des XFS-Dateisystems enthält am Anfang einen „XFSB“-String, Werte der Dateisystemparameter und viele Nullen. Ein gültiger Superblock enthält niemals Daten ungleich Null im Bereich von 0x100..0x200 Bytes. Diese Eigenschaft erleichtert die Bestimmung der Gültigkeit des Superblocks.
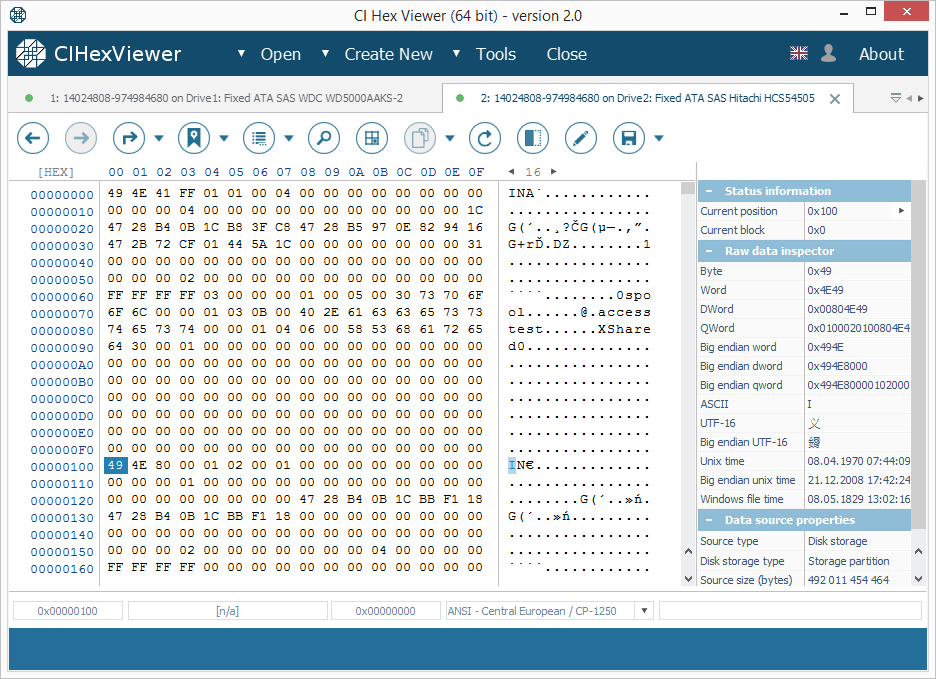
In diesem XFS-Dateisystem befindet sich der I-Nodes-Block mit einem Versatz von 64 KB. In den RAID 0- und RAID 5-Layouts mit der Standard-Stripe-Größe von 64 KB befindet sich der I-Nodes-Block an einem Null-Offset der Datenpartition von Drive2.
I-Nodes können durch die Zeichenfolge "IN" (Bytefolge "49 4E") am Anfang jedes 256 (0x100) Byte-Blocks identifiziert werden. Jeder I-Node beschreibt ein Dateisystemobjekt.
Die obere Ziffer des dritten Bytes definiert den Typ des Objekts. 4X Byte gibt ein Verzeichnis und 8X eine Datei an.
In Abbildung 2 kennzeichnet der erste I-Node ein Verzeichnis und der zweite – eine Datei.
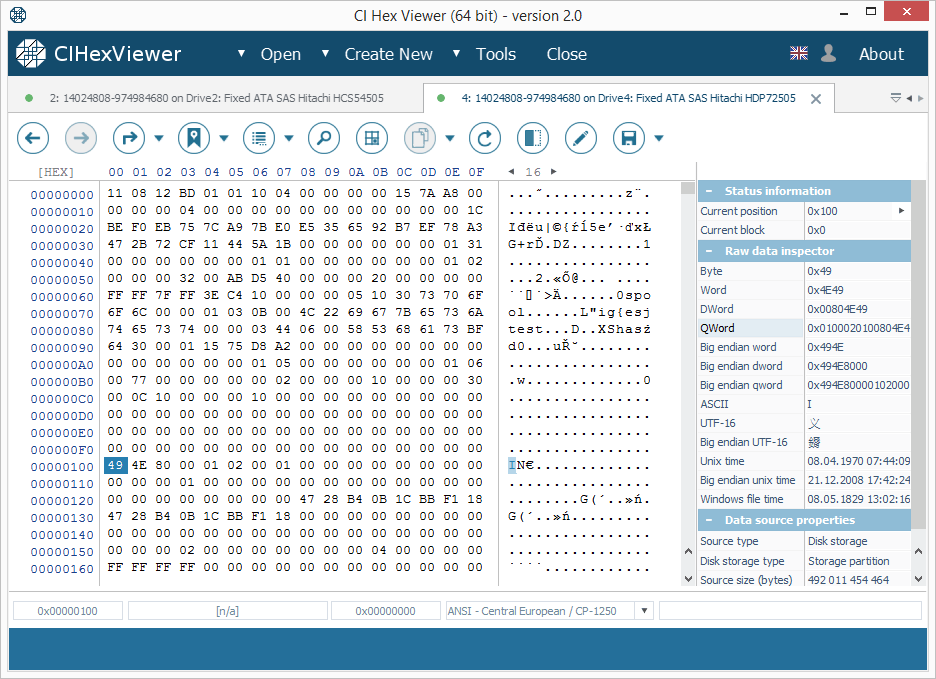
Der Paritätsblock enthält eine Mischung von Daten aus Datenblöcken anderer Laufwerke. Es kann aussehen wie "Quatsch" mit sichtbaren Datenfragmenten aus Datenblöcken.
Auch wenn der Paritätsblock im Gegensatz zum Superblock eine gültige XFSB-Zeichenfolge enthält, umfasst der Daten ungleich Null im Bereich von 0x100 ... 0x200 Byte. Das unterscheidet den vom Superblock. Bitte beachten Sie auch, dass der Paritätsblock normalerweise viel mehr Bytes ungleich Null enthält.
Anhand dieses bekannten Inhalts und unter der Annahme, dass der Startblock der erste Block der Datenpartition des angegebenen Laufwerks ist, können Sie die RAID-Konfiguration definieren:
RAID 5:
- Nur ein erster Block enthält den Superblock (Abb. 1).
- Wenn die Stripe-Größe 64 KB (für TeraStation üblich) beträgt, enthält einer der ersten Blöcke I-Nodes. Der erste I-Node gibt ein Verzeichnis an (das Stammverzeichnis). Wenn das Stammverzeichnis nur wenige Dateien enthielt, werden deren Namen im Hauptteil des I-Nodes angegeben (wie in Abb. 2).
- Der Startblock des dritten Laufwerks enthält die Daten- oder I-Nodes-Tabelle.
- Der Startblock des vierten Laufwerks enthält die Parität (Abb. 3).
- Das Anwenden der XOR-Operation auf Bytes von den Startblöcken jeder Platte an derselben Byteposition ergibt ein Ergebnis von Null.
Man kann die RAID 5-Konfiguration als RAID mit nur einem Superblock im Startblock und der Parität definieren. Die XOR-Operation über die Bytes jedes Startblocks an derselben Byteposition ergibt das Ergebnis Null.
Die Reihenfolge der Laufwerke ist wie folgt: Das Laufwerk mit dem Superblock ist das erste; das Laufwerk mit dem Stammverzeichnis – das zweite; das Laufwerk mit der Parität – das vierte; das restliche Laufwerk – das dritte. Das Paritätsprüfungsverfahren umfasst die folgenden Schritte:
- Wählen Sie einen Partitionsversatz mit Daten ungleich Null.
- Führen Sie einen Rechner aus (z. B. einen Windows-Standardrechner).
- Wählen Sie "Ansicht" als "Wissenschaftlich" oder "Programmieren" und wechseln Sie vom "Dez"- in den "Hex"-Modus.
- Geben Sie die hexadezimale Ziffer des ersten Laufwerks ein und drücken Sie die Taste "Xor".
- Geben Sie die hexadezimale Ziffer des nächsten Laufwerks mit genau demselben Versatz ein und drücken Sie erneut "Xor".
- Wiederholen Sie den Vorgang bis zum letzten Laufwerk. Bevor Sie die Ziffer des letzten Laufwerks eingeben, muss der Rechner dieselbe Nummer anzeigen wie an der angegebenen Position der letzten Festplatte. Die 'Xor'-Operation ergibt Null.
Ein Wert ungleich Null für einen der Versätze zeigt entweder einen Berechnungsfehler oder das Fehlen der Parität an.
RAID 0:
- Nur ein erster Block enthält den Superblock (Abb.1);
- Wenn die Stripe-Größe 64 KB (für TeraStation üblich) beträgt, enthält einer der ersten Blöcke I-Nodes. Der erste I-Node muss ein Verzeichnis (das Stammverzeichnis) angeben. Wenn das Stammverzeichnis Dateien enthält, werden deren Namen im Hauptteil des I-Nodes angegeben (wie in Abb. 2).
- Andere erste Blöcke enthalten keine anderen Superblöcke oder Paritäten.
- Andere Laufwerke enthalten möglicherweise mehr I-Nodes im ersten Block.
Man kann die RAID 0-Konfiguration als RAID mit nur einem Superblock im Startblock und ohne Parität definieren.
Die Reihenfolge der Laufwerke ist wie folgt: Das Laufwerk mit dem Superblock ist das erste; das Laufwerk mit dem Stammverzeichnis ist das zweite. Das dritte und das vierte Laufwerk können nicht gleichzeitig identifiziert werden, aber Sie können beide prüfen und herausfinden, welches der beiden Laufwerke das richtige ist.
RAID 10/0+1:
- Die ersten Blöcke von zwei Laufwerken enthalten einen gültigen Superblock (Abb. 1).
- Die anderen beiden Laufwerke enthalten Daten im Startblock und bei einer Stripe-Größe von 64 KB – I-Nodes.
Man kann die RAID 10/0 + 1-Konfiguration als RAID mit zwei Superblöcken in den Startblöcken definieren.
Die Reihenfolge der Laufwerke ist wie folgt: Das Laufwerk mit dem Superblock ist das erste, das Laufwerk ohne Superblock (Daten oder I-Nodes) ist das zweite. Diese Konfiguration hat zwei solcher Paare und beide können für die Datenwiederherstellung verwendet werden.
RAID 1 und mehrteilige Speicher:
- Die ersten Blöcke jedes Laufwerks enthalten einen gültigen Superblock (Abb. 1).
Man kann RAID 1 und einen mehrteiligen Speicher als RAID mit Superblöcken in allen Startblöcken definieren.
Die Reihenfolge der Laufwerke ist wie folgt: Jedes Laufwerk von RAID 1 liefert alle Daten. Bei einem mehrteiligen Speicher verfügt jedes Laufwerk über ein separates gültiges Dateisystem.
Wenn das Analyseverfahren zu einem widersprüchlichen Ergebnis führt und Sie hinsichtlich der Reihenfolge der Laufwerke immer noch unsicher sind, prüfen Sie alle Kombinationen aus und wählen Sie die passende aus.
Beachten Sie: UFS Explorer ändert die Daten auf dem Speicher nicht. Sie können verschiedene RAID-Kombinationen testen, bis Sie die richtige erhalten.
Schlussnoten
Nachdem Sie die richtige RAID-Konfiguration für die NAS-Laufwerke herausgefunden haben, können Sie mit dem Datenwiederherstellungsverfahren selbst fortfahren. Der gesamte Vorgang wird Schritt für Schritt in der Anleitung zur NAS-Wiederherstellung erläutert und im Video-Tutorial zur Datenrettung von NAS demonstriert.
Im Falle einer physischen Beschädigung wird es jedoch dringend empfohlen, Ihr NAS zur Datenwiederherstellung in ein spezialisiertes Labor zu bringen, um Datenverlust zu vermeiden.
Wenn Sie sich nicht sicher sind, ob Sie die Datenrettung selbst durchführen können oder Zweifel an der RAID-Konfiguration Ihres NAS haben, wenden Sie sich an die professionellen Dienste von SysDev Laboratories.
Letzte Aktualisierung: 19. August 2022