Linux: Причини невдалого відновлення даних
Операційна система Linux постійно зростає своєю популярністю серед більшої групи користувачів. Його чітка перевага полягає насамперед у вільному розповсюдженні. Крім того, ця операційна система пропонує величезну кількість версій та їхніх похідних, які охоплюють різноманітні потреби користувачів у пристроях, починаючи від мобільних телефонів та суперкомп'ютерів.
Linux OS використовує різні файлові системи, що включають Ext2, Ext3 і Ext4, XFS, ReiserFS, JFS (JFS2) і т.д. Файлові системи Linux відрізняються за функціональністю, кожна з яких обслуговує певні цілі. У процесі видалення файлів кожен поводиться по-своєму, забезпечуючи різні результати відновлення, а іноді навіть при невдалому відновленні.
Інформація, наведена у цій статті, допомагає зрозуміти загальні принципи роботи операційної системи Linux і причини частої невдачі відновлення видалених файлів з точними розмірами та іменами з файлових систем Linux. Наше програмне забезпечення для відновлення даних дозволяє досягти максимально можливого результату відновлення навіть у складних випадках. Для отримання додаткової інформації зверніться до програмних продуктів.
Як організовані дані?
Як і більшість інших файлових систем, файлові системи Linux використовують організацію блокових даних. На логічному рівні накопичувачі даних працюють в невеликих блоках даних - секторах - зазвичай розміром 512 байт. Можна уявити сектори зберігання як клітини з порядковими номерами. При запису фрагментів даних беруть один або більше таких секторів. При читанні драйвера зберігання адресує цей сектор для даних.
Для оптимізації адресації диска файлова система об'єднує рівні набори секторів на блоки адресується з драйвером файлової системи на логічному рівні. Мінімальний розмір блоку - один сектор. Більшість файлових систем, включаючи файлові системи Linux, використовують блоки як найменший адресний дисковий блок. Зазвичай файл або його фрагмент розміром менше одного блоку займає весь блок. Деякі файлові системи, такі як ReiserFS, можуть використовувати залишковий простір всередині блоку для виділення невеликих файлів і фрагментів файлів.
Зазвичай дані на сховищі організовані таким чином: файл виділяється в блок; якщо файл перевищує розмір блоку, файлова система надає ще один блок для виділення файлу (за винятком випадків, подібних до ReiserFS). Дані записуються у вільні дискові блоки, які не використовуються будь-якими файлами або метаданими (технічна інформація файлової системи).
Вільний простір і фрагментація
Багато послідовних або одночасних запитів "створити файл" , "додати дані" , "скоротити дані" , "видалити файл" уможливлюють фрагментацію вільного місця у файловій системі .
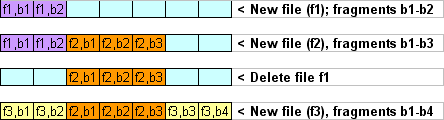
Рисунок 1. Фрагментація
На рисунку 1 показаний найпростіший приклад фрагментації. На момент написання файлу 3 не було місця для послідовного запису фрагментів файлів, отже фрагменти одного і того ж файлу були розподілені на два не пов'язаних вільних блоку. На практиці великі файли можуть складатися з до сотень незв'язаних фрагментів даних по кілька блоків кожен.
Файлова система негайно не стерти фрагменти файлу під командою 'delete', а вільне місце, яке займають ці фрагменти. Це місце сприймається новим файлом як вільний. З цієї причини файл фактично залишається відновлюваним, якщо його не буде перезаписано новим.
Як пов'язані фрагменти?
Файлова система використовує спеціальні агенти, що описують файли - інформаційні вузли (коротко - inodes ) - для зв'язку інформації про фрагменти файлів. Ця інформація включає опис типу об'єкта, розміру, таблиці розподілу / списку / дерева .
Зчитуючи інод, файлова система може визначити тип об'єкта і вирішити подальші операції - читання / запис / обробка. Розмір об'єкта розповідає про кількість блоків, зайнятих об'єктом. І, нарешті, виділення об'єктів дає інформацію про фактичне розташування блоків даних.
Дані розподілу об'єктів організовуються наступним чином: Ключовою частиною цих даних є масив, список або B-дерево покажчиків на блоки даних або на безперервні фрагменти блоків. Перша частина або корінь цієї інформації зберігається як частина inode.
Проблема відновлення
Зазвичай, файлові системи Linux очищають частину інформації про inode після видалення файлу. Вони заповнюють інформацію про розмір об'єкта, тип об'єкта / режим і виділення з нулями, що призводить до втрати всієї інформації про файл. Припустимо, що файли 2 і 3 на малюнку 1 є RAW-зашифрованими файлами без заголовків, і обидва брали повні блоки, і обидва були видалені. В результаті жодна інформація про розміщення файлів не дозволила програмному забезпеченню відновлення даних виявити межі файлу 2 і файлу 3. На практиці ситуації, які погіршують відновлення, на жаль, занадто поширені для файлових систем Linux. На це зазвичай впливають такі фактори, як фрагментація важких файлів.
Рішення
На щастя, програмне забезпечення для відновлення даних пропонує набір методів відновлення, але без гарантій 100% результату . Вони включають:
-
Аналіз журналу файлової системи. Попередні версії дескрипторів файлів можуть залишатися в журналі.
-
Аналіз неповних структур. Програмне забезпечення може передбачати файли файлової системи непротіреними фрагментами метаданих файлів, які можуть бути на диску.
-
Пошук на основі підпису: програмне забезпечення шукає відомі фрагменти файлів і робить припущення щодо вмісту наступних фрагментів. Але часто результати відновлення не дають точних розмірів файлів, за винятком випадків, коли знайдений заголовок файлу, який сам по собі містить розмір файлу. Цей метод безпомічний для випадків важкої фрагментації.
-
Аналіз статистичних фрагментів: Програмне забезпечення припускає посилання на фрагменти на основі статистичних методів аналізу даних. Цей метод може бути корисним для гомогенних файлів (більшість зображень bmp, деяких архівів тощо), але є безпорадним для гетерогенного вмісту (наприклад, CD / DVD-зображення тощо).
-
Пошук втрачених структур файлової системи: Програмне забезпечення знаходить втрачені структури файлової системи, допомагаючи визначити компонування втрачених фрагментів.
Якщо ви плануєте проводити відновлення даних самостійно, будьте готові до великої кількості ручної роботи з аналізом неназваних файлів або фрагментів файлів, оскільки більшість програм відновлення даних часто призводять до неповного відновлення після відновлення файлових систем Linux.
Продукти для відновлення даних UFS Explorer розроблені з потужними механізмами, включаючи пошук IntelliRAW ™ за допомогою підписів, що дозволяє користувачам розпізнавати типи файлів і аналіз структур файлової системи. Ефективні методи програмного забезпечення дають можливість досягти найвищого результату відновлення з мінімальними зусиллями.
Останнє оновлення: 5 серпня 2022