Cómo se identifica el orden de las unidades en un NAS basado en XFS
En general, los dispositivos NAS, como, por ejemplo, LinkStation y TeraStation de Buffalo, Iomega StorCenter y Synology, se basan en un tipo de RAID de software ensamblado a partir de las particiones de datos (las particiones más grandes) de una serie de discos. Y el sistema de archivos XFS se distribuye entre estas particiones de datos. Así que, es imprescindible conocer el orden correcto de las unidades en el sistema RAID en el que se basa un NAS para poder ensamblarlo correctamente y luego proceder a la recuperación de datos.
En el siguiente artículo, se explica cómo se puede identificar el orden de las unidades en un NAS basado en XFS y compuesto de cuatro discos, como Buffalo TeraStation, Iomega StorCenter, Synology y otros modelos de NAS similares.
Formas y medios
Antes de comenzar a recuperar datos de un NAS basado en XFS, se debe descubrir el orden de las unidades y los parámetros del RAID en el que está basado.
Una manera posible de identificar el orden de los discos es analizar su contenido hexadecimal de acuerdo con los fragmentos de datos conocidos al inicio de las particiones de datos. CI Hex Viewer proporciona un conjunto de medios para realizar dicho análisis. Al mismo tiempo, algunas aplicaciones avanzadas de recuperación de datos ofrecen una forma mucho más sencilla de identificar los parámetros de RAID: la detección automática de RAID por el software.
Por regla general, los dispositivos NAS no brindan acceso directo a bajo nivel a sus sistemas de archivos, y los modelos en XFS no son una excepción. Así que, se debe desensamblar el almacenamiento en cuestión y conectar sus unidades a una PC. Por favor, lea el artículo Cómo conectar una unidad IDE/SATA a una PC para obtener instrucciones detalladas. Además, se puede ver los tutoriales de vídeo sobre cómo conectar unidades a la placa base de una computadora o conectarlas externamente usando un adaptador USB a SATA/IDE.
Detección automática de los parámetros de RAID
Los almacenamientos conectados en red con el sistema de archivos XFS generalmente están basados en un RAID de software de múltiples dispositivos (Multiple Devices o MD RAID en inglés). Este tipo de RAID se crea con la ayuda de la conocida utilidad mdadm y puede tener una de las configuraciones lineales (JBOD), de stripes/bandas (RAID 0) o de duplicación/mirror (RAID 1), o basarse en RAID 5 o RAID 6. La utilidad crea pseudoparticiones con metadatos que son suficientes para ensamblar un RAID automáticamente.
SysDev Laboratories ofrece una serie de programas UFS Explorer, utilidades potentes que soportan la detección, la construcción y la recuperación de datos automáticas de varios tipos de RAID de software. UFS Explorer RAID Recovery se desarrolló especialmente para trabajar con los sistemas complejos de RAID, mientras que UFS Explorer Professional Recovery representa un enfoque profesional para la recuperación de datos de varios dispositivos, incluidos los RAID de cualquier complejidad. Para obtener más información, por favor, consulte las especificaciones técnicas del producto correspondiente.
Para que el programa UFS Explorer RAID Recovery ensamble automáticamente un RAID:
- Descargue, instale y ejecute el software;
- Conecte las unidades de su NAS a una computadora host o abra los archivos de imagen de sus discos en la interfaz del programa;
- El software ensamblará su RAID de manera automática y lo agregará a la lista de dispositivos conectados para futuras operaciones.
Si la detección automática de RAID está desactivada en la configuración del programa:
- Abra RAID Builder, seleccione cualquier partición de datos del RAID de software y agréguela como componente de un nuevo RAID virtual;
- Una vez agregada la partición y detectados los metadatos MD, el software le preguntará si debe ensamblar el RAID automáticamente;
- Pulse 'Sí', y el programa cargará las particiones del disco en el orden correcto y con los parámetros de RAID correctos;
- Haga clic en 'Construir este RAID' para ensamblar su RAID y procesarlo en UFS Explorer.
Nota: Si los parámetros de RAID del NAS se restablecieron a un nivel diferente de RAID, el tipo de arreglo, el orden de los discos y el tamaño de stripe anteriores se deben definir manualmente. Pulse 'No' en el cuadro de diálogo del software, rechace el ensamblaje automático de RAID y especifique los parámetros necesarios a mano.
Análisis del contenido de los discos
Otra forma de determinar los parámetros de RAID e identificar con precisión el orden de sus unidades es realizar un análisis profundo del contenido de las unidades. CI Hex Viewer brinda medios efectivos para el análisis cualitativo a bajo nivel de datos.
Y para prepararse para el procedimiento, se debe hacer lo siguiente:
En Linux: ¡no monte los sistemas de archivos de las unidades del NAS!
En Mac: ¡no realice ningún diagnóstico, reparación ni operaciones similares en los discos usando la Utilidad de discos!
- Arranque su PC, instale y ejecute CI Hex Viewer;
En Windows XP y versiones anteriores: ejecute el software como administrador;
En Windows Vista/7/8/10 con UAC: ejecute el software como administrador utilizando el menú contextual;
En macOS: inicie sesión como administrador del sistema al ejecutar el programa;
En Linux: desde la línea de comandos ejecute 'sudo cihexview' o 'su root -c cihexview'.
- Haga clic en "Abrir" y luego seleccione "Un disco físico" (Control+Mayús+"O"); abra la partición de datos de cada unidad del NAS.
Cada disco del NAS tiene la misma estructura de partición: de 1 a 3 particiones de "sistema" pequeñas (de tamaño total de aproximadamente unos gigabytes) y una partición de datos grande (que generalmente ocupa más del 95% de la capacidad total de la unidad). Para obtener más información sobre las particiones, lea el artículo correspondiente.
Configuración de RAID y detección avanzada del orden de las unidades
Para analizar el contenido de las unidades, abra cada partición de datos en CI Hex Viewer.
A continuación, se puede encontrar un ejemplo del análisis de contenido de un arreglo RAID 5 con el tamaño de banda de 64KB y el sistema de archivos XFS.
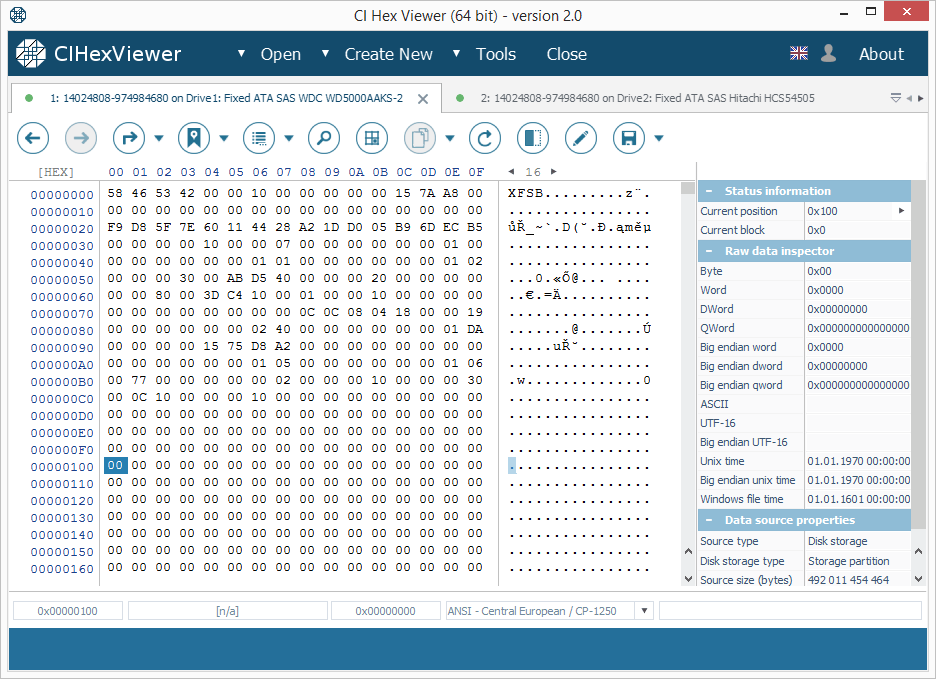
El bloque inicial (o superbloque) del sistema de archivos XFS contiene una cadena "XFSB" al principio, los valores de parámetros del sistema de archivos y muchos ceros. Un superbloque válido nunca contiene datos distintos de ceros en un rango de 0x100 a 0x200 bytes. Esto facilita la determinación de la validez del superbloque.
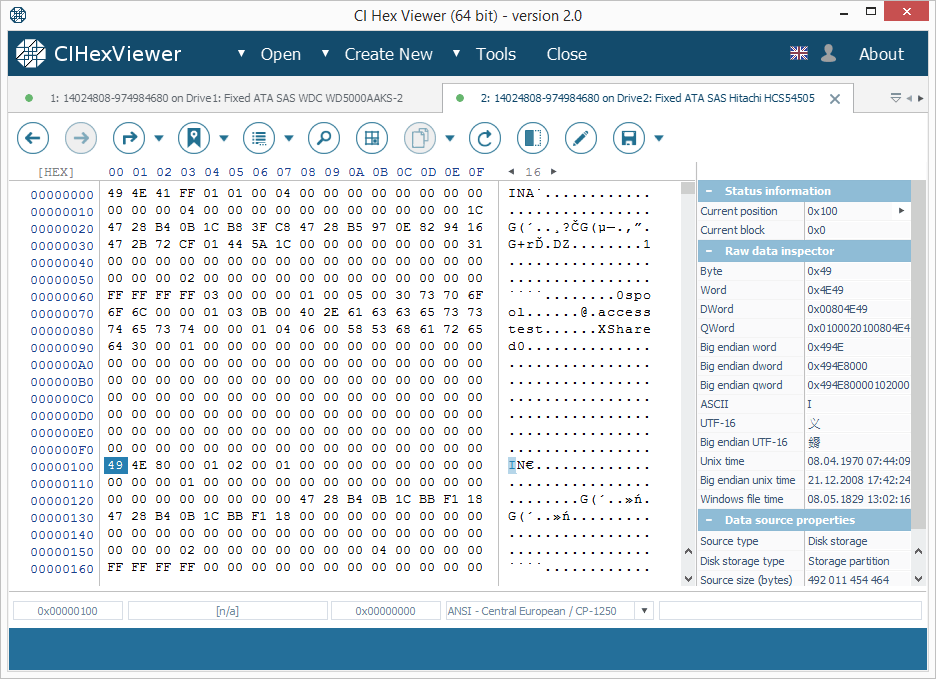
En este sistema de archivos XFS, el bloque de I-nodos se encuentra en un offset de 64KB. En RAID 0 y RAID 5 con el tamaño de stripe predeterminado de 64KB, el bloque de I-nodos está ubicado en un offset cero de la partición de datos de Drive2.
Los I-nodos se pueden identificar por la cadena "IN" (secuencia de bytes "49 4E") al comienzo de cada bloque de 256 (0x100) bytes. Cada I-nodo describe un objeto del sistema de archivos.
El dígito superior del tercer byte define el tipo del objeto. 4X byte indica un directorio y 8X – un archivo.
En la Imagen 2, el primer I-nodo indica un directorio y el segundo – un archivo.
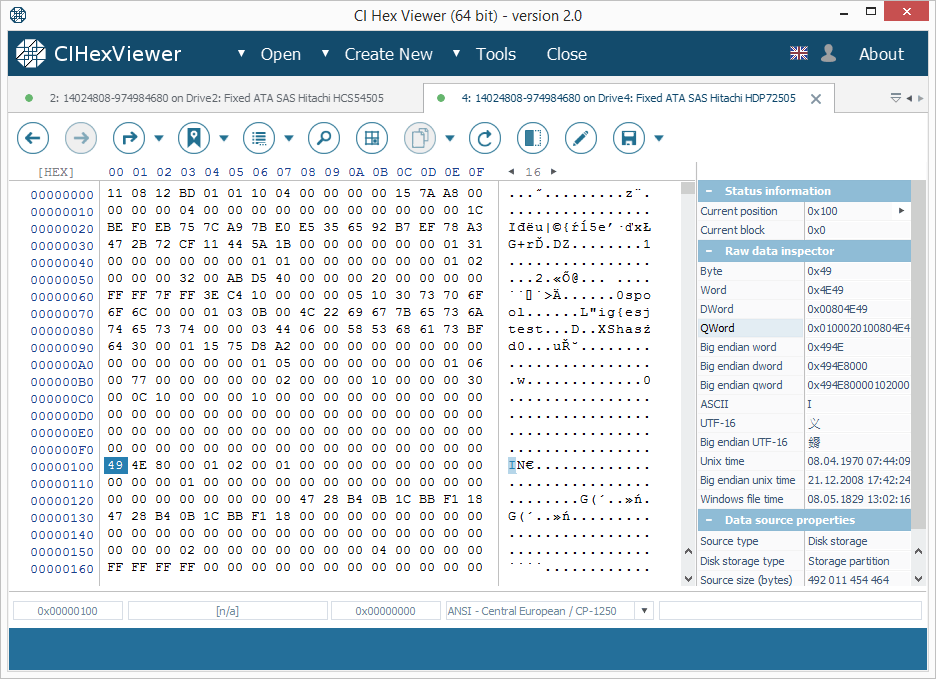
El bloque de paridad contiene un conjunto de datos de los bloques de datos de otras unidades. Puede parecer "basura" con unos fragmentos visibles de datos de los bloques de datos.
Incluso si el bloque de paridad contiene una cadena "XFSB" válida, a diferencia del superbloque, contiene datos distintos de cero en un rango de 0x100 a 0x200 bytes; eso es lo que lo diferencia del superbloque. Cabe resaltar que el bloque de paridad generalmente contiene muchos más bytes distintos de cero.
Ahora, utilizando este contenido conocido y suponiendo que el bloque inicial es el primer bloque de la partición de datos de la unidad dada, puede definir la configuración de RAID:
RAID 5:
- Únicamente un solo primer bloque contendrá el superbloque (Imagen 1);
- Si el tamaño de stripe es de 64KB (habitual para TeraStation), uno de los primeros bloques contendrá I-nodos; el primer I-nodo indica un directorio (el directorio raíz). Si el directorio raíz contiene varios archivos, sus nombres se mencionan en el cuerpo del I-nodo (como en la Imagen 2);
- El bloque inicial de la tercera unidad contendrá los datos o la tabla de I-nodos;
- El bloque inicial de la cuarta unidad contendrá la paridad (Imagen 3);
- La aplicación de la operación XOR a los bytes de los bloques iniciales de cada disco en la misma posición de byte da un resultado cero.
Se puede definir la configuración de RAID 5 como RAID con un solo superbloque en el bloque inicial y la paridad. La operación XOR aplicada a los bytes de cada bloque inicial en la misma posición de byte da un resultado cero.
El orden de las unidades es el siguiente: la unidad con el superbloque es la primera; la unidad con el directorio raíz – la segunda; la unidad con la paridad – la cuarta; y la unidad restante - la tercera. El procedimiento de verificación de la paridad incluye los siguientes pasos:
- Elija un offset de partición con datos distintos de cero;
- Ejecute una calculadora (por ejemplo, la calculadora estándar de Windows);
- Configure el parámetro 'Ver' como 'Científico' o 'Programación', cambiando del modo 'Dec' al modo 'Hex';
- Escriba el dígito hexadecimal de la primera unidad y pulse el botón 'Xor';
- Escriba el dígito hexadecimal de la siguiente unidad exactamente en el mismo offset y pulse 'Xor' de nuevo;
- Repita el procedimiento para el resto de las unidades. Antes de ingresar el dígito hexadecimal de la última unidad, la calculadora debe mostrar el número coincidente con aquello de la posición especificada del último disco. La operación 'Xor' dará cero.
Un valor distinto de cero para cualquiera de los offsets indica un error de cálculo o la ausencia de paridad.
RAID 0:
- Un solo primer bloque contiene el superbloque (Imagen 1);
- Si el tamaño de stripe es de 64KB (habitual para TeraStation), uno de los primeros bloques contendrá I-nodos; el primer I-nodo debe indicar un directorio (el directorio raíz). Si el directorio raíz contiene más archivos, sus nombres se especifican en el cuerpo del I-nodo (como en la Imagen 2);
- Otros primeros bloques no contienen superbloques ni paridad;
- Otros discos pueden contener más I-nodos en el primer bloque.
Se puede definir la configuración de RAID 0 como RAID con un solo superbloque en el bloque inicial y sin paridad.
El orden de los discos es el siguiente: el disco con el superbloque es el primero; y uno con el directorio raíz es el segundo. Los discos 3 y 4 no se pueden identificar a la vez, pero puede probar ambos y determinar cuál de ellos es el correcto.
RAID 10/0+1:
- Los primeros bloques de dos unidades contienen un superbloque válido (Imagen 1);
- Otras dos unidades contienen datos en el bloque inicial y, en caso del tamaño de stripe de 64KB – I-nodos.
Se puede definir la configuración de RAID 10/0+1 como RAID con dos superbloques en los bloques iniciales.
El orden de las unidades es el siguiente: la unidad con el superbloque es la primera, la unidad sin superbloque (datos o I-nodos) es la segunda. Esta configuración tiene dos pares de dicho tipo y ambos se pueden usar para la recuperación de datos.
RAID 1 y almacenamientos de múltiples partes:
- Los primeros bloques de cada unidad contienen un superbloque válido (Imagen 1).
Se puede definir RAID 1 y un almacenamiento de múltiples partes como RAID con superbloques en todos los bloques iniciales.
El orden de las unidades es el siguiente: cualquier unidad de RAID 1 proporciona todos los datos. En el caso de un almacenamiento de varias partes, cada unidad tiene un sistema de archivos válido independiente.
Si el procedimiento de análisis da un resultado contradictorio y aún no está seguro en cuanto al orden de las unidades, pruebe todas las combinaciones y elija la correcta.
Nota: el software UFS Explorer no modifica los datos en el almacenamiento. Por lo tanto, el usuario puede probar diferentes configuraciones de RAID hasta que encuentre la adecuada.
Notas finales
Después de descubrir la configuración correcta de RAID aplicada a las unidades del NAS, uno puede continuar con el procedimiento de recuperación de datos en sí. El proceso se explica paso a paso en el manual de recuperación de datos de un NAS y se demuestra en el vídeo de recuperación de archivos de un NAS.
Aún así, en caso de daño físico, para evitar la pérdida de datos, se recomienda llevar su NAS a un laboratorio especializado en la recuperación de datos.
Si no está seguro de poder realizar operaciones de recuperación de datos por sí mismo o tiene dudas sobre la configuración de RAID de su NAS, no dude en solicitar los servicios profesionales proporcionados por SysDev Laboratories.
Última actualización: el 05 de octubre de 2022