Was kann getan werden, um gelöschte Dateien unter Linux wiederherzustellen?

Die Gewohnheit, unerwünschte Dateien über die Befehlszeile zu löschen, wird für viele Linux-Benutzer zur Ursache Datenverlusts, da wenn man diese Methode verwendet, kann man nicht zum Papierkorb gehen und versehentlich gelöschte Elemente an ihrem ursprünglichen Speicherort zurückbringen. Selbst für diejenigen, die die Benutzeroberfläche oder die Entf-Taste bevorzugen, kann es jedoch vorkommen, dass versehentlich gelöschte Dateien wiederhergestellt werden müssen, inbesondere nachdem der Papierkorb, in dem sie aus Sicherheitsgründen aufbewahrt werden, geleert wurde. Glücklicherweise ist die Datei in beiden Fällen unabhängig von den Angaben in der Verzeichnisliste nicht sofort gelöscht und ihre Daten befinden sich möglicherweise noch auf der Festplatte, solange der Bereich durch neue Informationen nicht überschrieben wird, wodurch die Möglichkeit der Datenrettung besteht. Dennoch können die nach dem Löschvorgang getroffenen Aktionen zusammen mit einigen anderen Faktoren die Erfolgswahrscheinlichkeit beeinflussen.
Retten Sie gelöschte Dateien von den Dateisystemen von Linux
Die zum Löschen einer Datei verwendeten internen Mechanismen werden von dem auf einem Speichergerät zugrunde liegenden Dateisystem bestimmt. Obwohl die Liste der Dateisysteme, die vom Kernel unterstützt werden, sehr lang ist, gebrauchen gängige Linux-Distributionen (wie Ubuntu, Mint, Fedora, elementary OS, OpenSUSE usw.) Ext2/Ext3/Ext4, XFS, JFS, ReiserFS, UFS und Btrfs während FAT32/exFAT auf den meisten Wechseldatenträgern verwendet wird. Jedes von ihnen hat bestimmte Besonderheiten, die sich auf die Qualität der Wiederherstellungsergebnisse auswirken: Beispielsweise haben Dateien, die von XFS und Btrfs gelöscht wurden, sehr hohe Abrufchancen, während Dateien von Ext2/Ext3/Ext4 aufgrund einer hohen Fragmentierung schlecht gerettet werden.
Hinweis: Weitere Informationen zu den Dateisystemen von Linux finden Sie in den Grundlagen von Dateisystemen. Wenn Sie die Möglichkeit erfolgreicher Datenwiederherstellung bewerten möchten, machen Sie sich mit den Artikeln vertraut, in den die Besonderheiten der Datenrettung in Abhängigkeit vom Betriebssystem und die Chancen für die Datenwiederherstellung beschrieben werden.
SysDev Laboratories empfiehlt UFS Explorer Standard Recovery als effektive Softwarelösung, die in der Lage ist, mit allen gängigen Linux-Dateisystemen zu arbeiten und Dateien, die sowohl auf einfachen als auch auf übergreifenden Volumen, einschließlich mdadm und LVM, vor der Löschung vorhanden waren, wiederherzustellen.
Beachten Sie: Gelöschte Dateien können wiederhergestellt werden, sofern sie mit anderen Informationen nicht überschrieben werden. Aus diesem Grund wird dringend empfohlen, alle Vorgänge mit dem Speicher, aus dem die Daten gelöscht wurden, zu beenden und sofort mit der Dateien-Wiederherstellung zu beginnen.
Beachten Sie: Wenn die Dateien von einer Solid-State-Disk (SSD) mit aktiviertem TRIM gelöscht wurden, ist es sehr wahrscheinlich, dass deren Inhalt durch den unmittelbar nach dem Löschen aufgerufenen Befehl zerstört wurde. Die erfolgreiche Rettung solcher Dateien ist normalerweise nicht möglich.
-
Um das Risiko, dass gelöschte Dateien von einem Benutzer/Prozess überschrieben werden, zu verringern, müssen Sie das System in einen Einzelbenutzermodus schalten und das Dateisystem des Problemverzeichnisses aushängen, indem Sie den Befehl "unmount" mit dem Namen der Festplatte oder dem Einhängepunkt ausführen. Wenn sich die gelöschten Dateien im "/root"-Verzeichnis befanden, das immer eingehängt ist, wird es dringend empfohlen, die Festplatte zu entfernen und sie als sekundäres Gerät an einen anderen Computer anzuschließen.
Hinweis: Sie können die Festplatte an das Motherboard des Computers anschließen oder das Laufwerk extern über einen USB-zu-SATA/IDE-Adapter verbinden, wie in den Anleitungen beschrieben.
-
Laden Sie den komprimierten Installer von UFS Explorer Standard Recovery herunter, wählen Sie die Option „Downloaden für Linux“, extrahieren Sie den Inhalt des heruntergeladenen Archivs und starten Sie den Installationsmanager, nachdem Sie Ihr Benutzerkennwort eingegeben haben. Verwenden Sie nicht den Speicher, der die gelöschten Daten enthält, um das Überschreiben zu vermeiden.
Hinweis: Wenn Sie Probleme mit der Installation des Programms haben, lesen Sie bitte die Installationsaweisung für UFS Explorer Standard Recovery.
-
Führen Sie das Programm aus und ändern Sie die Softwareeinstellungen im Einstellungsbereich.
-
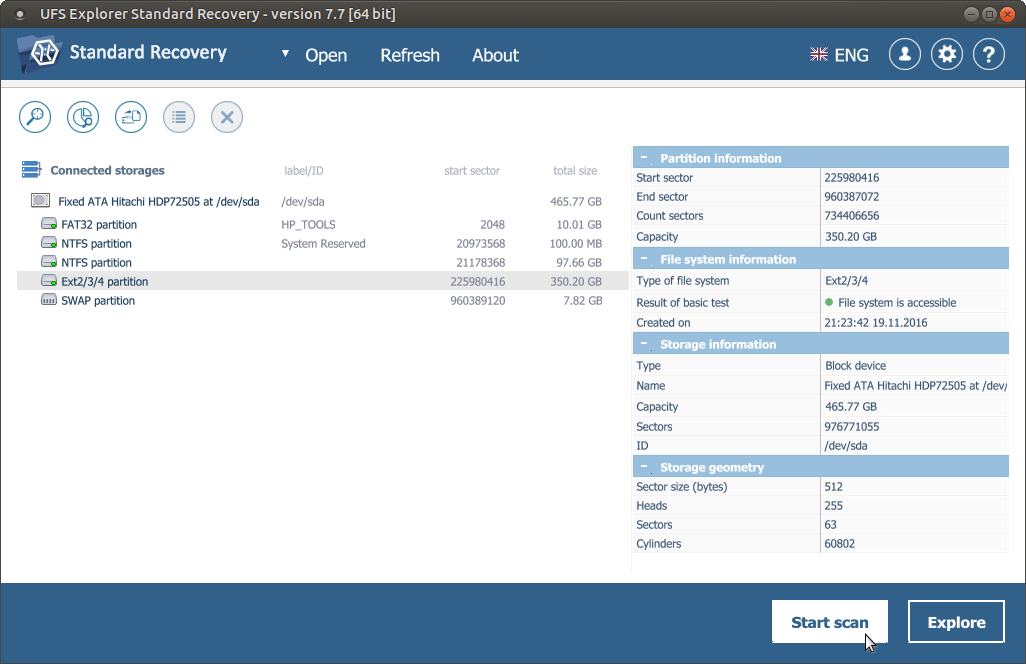
UFS Explorer Standard Recovery erkennt verfügbare Partitionen automatisch und zeigt sie in der Liste der angefügten Speicher im linken Bereich an. Wählen Sie die benötigte Partition nach Größe, Dateisystemtyp oder Inhalt aus, und scannen Sie sie nach verlorenen Daten mithilfe des entsprechenden Kontextmenüs des Speichers, der Schaltfläche "Scan starten" oder des Tools "Diesen Speicher scannen" in der Toolbar.
-
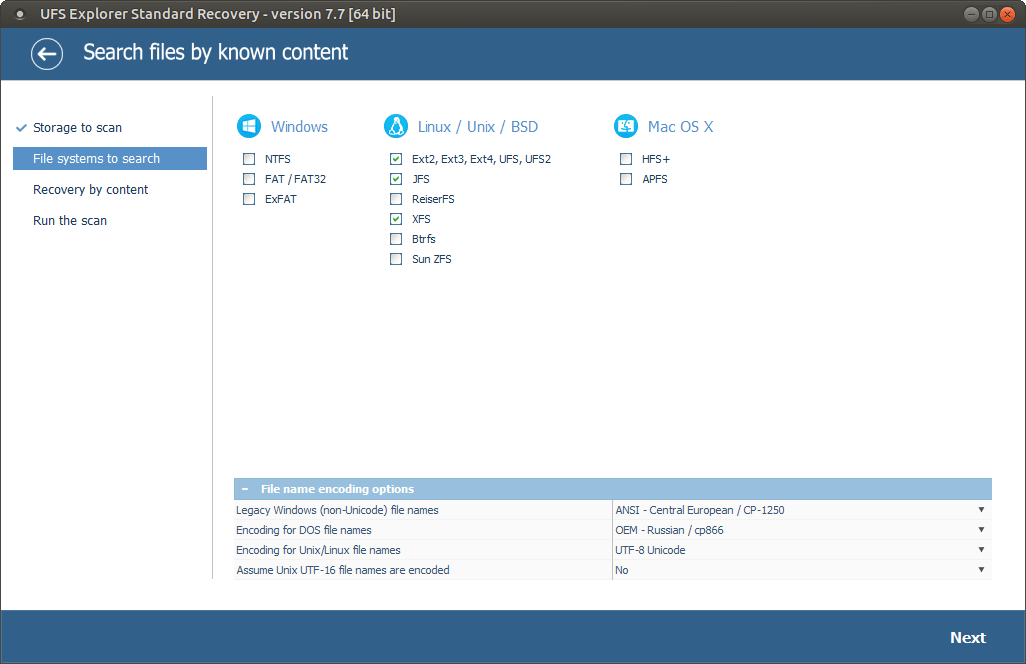
Richten Sie die bevorzugten Scan-Parameter ein. Wenn Sie möchten, dass der Prozess schneller ausgeführt wird, können Sie die Auswahl aller Dateisysteme mit Ausnahme des auf Ihrer Partition angewendeten aufheben und IntelliRAW deaktivieren. Klicken Sie anschließend auf "Scan starten" und warten Sie, bis der Vorgang abgeschlossen ist.
-
Überprüfen Sie die gefundenen Dateien und Ordner. Sie können nach Name, Datum oder Typ sortiert und im internen Viewer vorher beschaut werden. Schnelle und erweiterte Suchoptionen können auch verwendet werden, wenn Sie bestimmte Dateien suchen wollen.
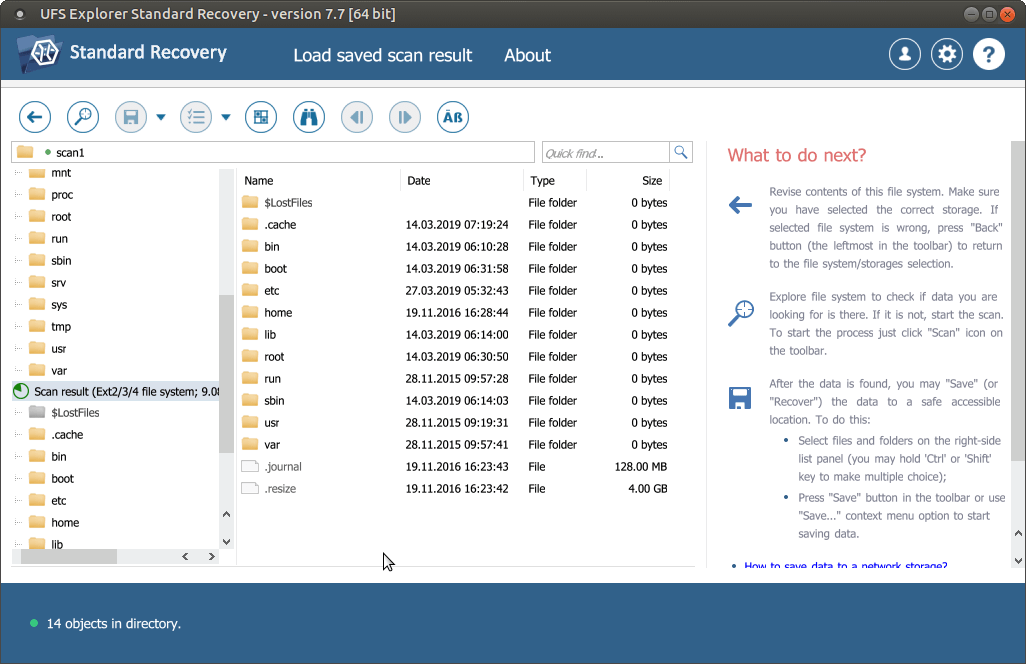
-
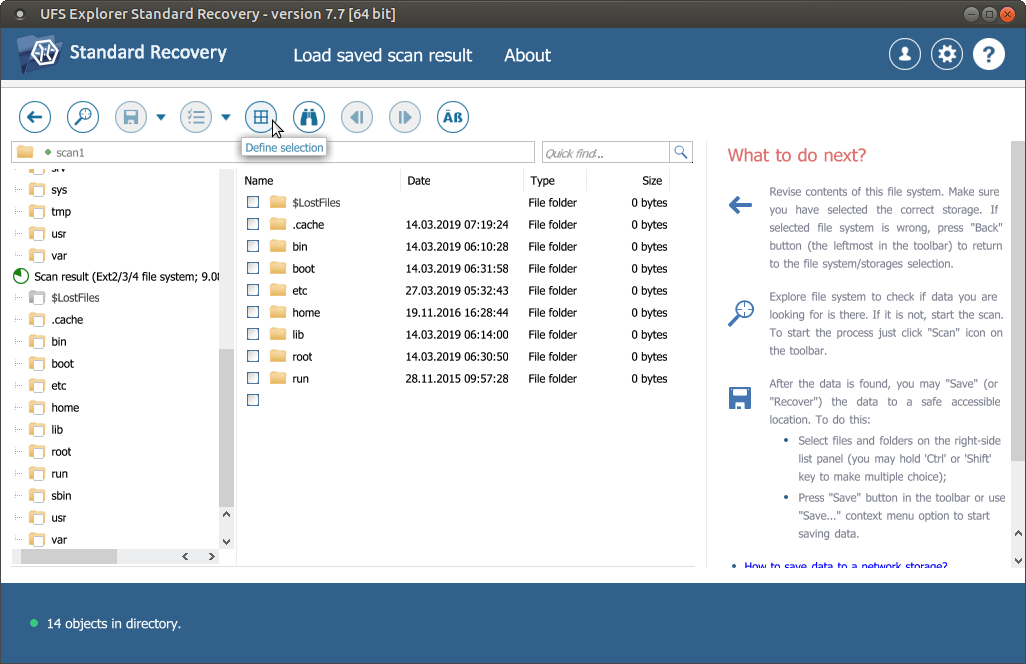
Klicken Sie auf die Schaltfläche "Auswahl bestimmen", wählen Sie die wiederherzustellenden Dateien und Ordner aus und drücken Sie "Auswahl speichern (retten)". Wählen Sie einen zusätzlichen Speicher zum Kopieren der Dateien, um das Überschreiben der Daten zu vermeiden.
Sehen Sie sich dieses kurze Video an, um das gesamten Verfahren selbst zu sehen:
Beachten Sie: Wenn die Daten aus dem "/root"-Verzeichnis verloren gingen und es nicht möglich ist, die Festplatte zu extrahieren und an einen anderen Computer anzuschließen, können Sie den Computer mit UFS Explorer Backup and Emergency Recovery CD für sichere Datenwiederherstellung starten. Weitere Informationen finden Sie unter Datenrettung von der Systempartition.
Letzte Aktualisierung: 09. August 2022